


What is a Knowledge Representation?
Translating mental models into machine-executable format

In this blogging series so far, I have been considering how AI might help with ethical decisions. Here is a recap of the main arguments:
Ethical automation (including AI) should help humans to make ethical decisions, so there is a need to challenge cognitive biases that can cause unfair judgments of others (posts 1 and 2).
A commonly recommended bias countermeasure is to seek out other perspectives. So the question is whether decision support tools can be designed to help with perspective switching (post 3).
Many features of a perspective can be understood as a mental model. This includes the concepts and concerns that stand out in a person’s experience. Such a mental model can be translated into a knowledge representation, which is a key foundation of AI (post 4).
The last post ("What is AI?") emphasised the importance of human experience and authorship in the design of AI systems and in particular their role in knowledge representations. In this post, I will describe in more detail what is meant by a knowledge representation, using non-technical language as far as possible.
Representing the world using symbols
A knowledge representation is a collection of formulations that can be interpreted by humans and machines. The representation is symbolic, in the sense that humans find it meaningful, while also being precise enough for machine processing using the rules of logic. This helps with transparency and reliability as explained in the last post. A knowledge representation can be divided into the following components:
Ontology: specifies what kind of things exist: What properties do they have? What higher class do they fit into? What are their subclasses? For an example ontology, the class “city” could belong to a more general class called “populated land area”, and have the properties “population”, “area”, “climate” etc. Different subclasses of “city” could be “capital city”, “regional city” or “port”).
Factual statements: these are about real things that exist (not abstract classes). They are called “instances”. Facts can state what particular instances of classes exist and what values do their properties have. E.g. “London is a city, and has a population of 8 million”.
Inference mechanisms: how to generate new statements from existing statements. The classifications in the ontology allow inference about properties of an instance depending on its class. Other types of inference can be “if … then …” type rules, or they can be more complex operations involving logical expressions.
Ontologies
Figure 1 shows a simplified ontology using the example of transport. The diagram is for illustration only and does not include all the possibilities.
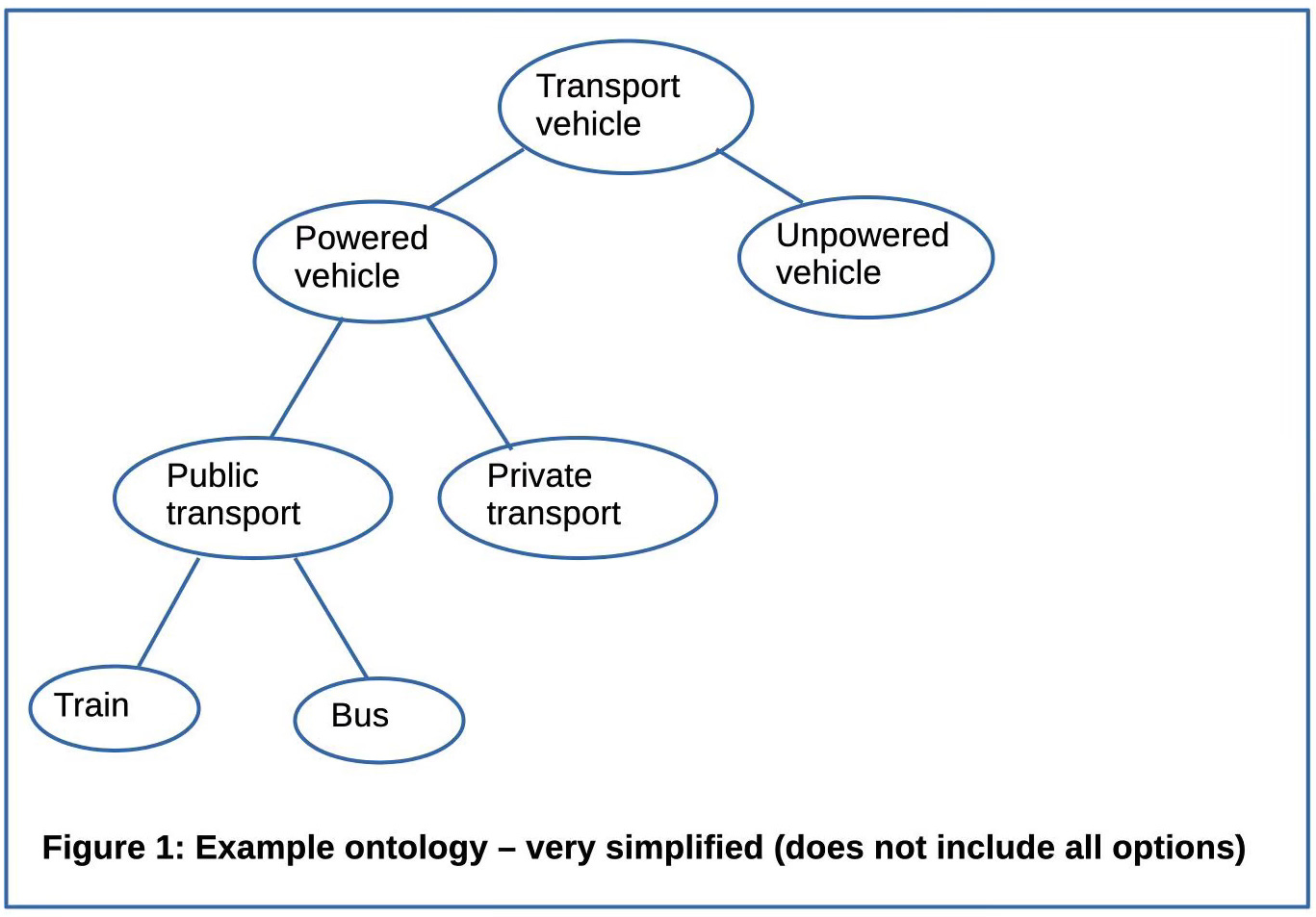
The ontology defines classes of transport (such as public, private etc). Each line means “is a kind of”. For example, a train is a kind of public transport. To ease understanding, the diagram does not contain all the details of ontologies that are used in real life.
A knowledge representation also includes actual entities in the real world. These are data items that are instances of the classes and are organised according to the ontology. So for example, “the 10:30am train from London to Manchester” would be an instance of the class “train”. The term “knowledge graph” is often used for data items that are connected together according to an ontology.
Ontology classes also have properties. For simplicity, these are not included in the diagram. As an example, the public transport class might have properties such as number of seats, route and timetable. So an actual vehicle that is public transport will have these details. In this way, ontologies provide automated reasoning because the properties of an entity can be deduced from the properties of the class it belongs to.
Human authorship vs machine learning
Ontologies can be generated automatically using machine learning. For example, ontology learning from text is an active research area, as is learning ontologies from the structure of databases (see for example this survey).
However, as argued in the last post, human authorship plays a key role because choices can be made explicitly about what concepts need more detailed representation.
Furthermore, rare but significant events can be experienced in real life, such as a rare disease, or an unusual set of circumstances causing an accident. Such non-typical situations need to be included in a knowledge representation, because they may not have wide representation in online text or databases, and therefore will be insufficient for training machine learning models. This also applies to lived experiences.
However, ontology authorship is a complex technical process with many similarities to software development. An additional process is needed for community engagement and participatory knowledge acquisition. Both processes need multi-disciplinary collaboration.
Multiple perspectives
If we look again at the ontology diagram above, it is clear that the classes could be organised differently. For example, an environmental expert who is interested in reducing carbon emissions might focus on the “powered vehicle” class and subdivide this into “fossil fuel powered” and “renewable energy powered”.
Blending multiple perspectives into a single ontology is difficult without causing unmanageable complexity. So it is easiest to design specialist ontologies separately and then use an ontology integration tool. (Many ontologies tend to be designed separately in practice). Ontology integration is an active research area.
However, for the purposes of decision support and for counteracting biases, it may not be necessary for ontologies to be integrated. Instead, the multiple perspectives could be represented as arguments or data visualisations that are informed by separate ontologies. Each perspective could then be available independently for consideration by a decision-maker.
Conclusion
In this post, I have given a brief non-technical overview of ontologies and how they are used to organise data items. Key take-aways are as follows:
Knowledge representations are formulations that can be interpreted by humans and machines. This provides transparency because the processing of a representation can be inspected more easily than with machine learning.
Human-authored ontologies can be used to capture rare situations which may not be well-represented in text or data that is used to train machine learning systems.
Multiple ontologies can represent multiple perspectives and can be used to inform decision support.
Notes
This blog post is human-produced, without any generative AI tool.